
Quinta guía definitiva de la serie SEO TÉCNICO. Hablamos de la indexación de nuestra web en Google.
- Qué es el SEO Técnico
- Operadores y Footprints de Google
- Arquitectura web SEO
- Cómo indexar mi web en Google
- Qué es Robots.txt y para qué sirve
- Qué es Crawl Budget
- Sitemaps SEO
- Cómo optimizar el wpo de mi web
- Contenido Duplicado y Thin Content
- Solucionar la Canibalización SEO
Robots.txt es uno de los archivos más importantes de nuestra web.
Si no lo tenemos correctamente optimizado podemos llegar, incluso, a bloquear a Google, que no pueda accedera nuestra web, no pueda posicionarla y no podamos ganar dinero. Poca broma.
Además, en los últimos tiempos Robots.txt ha sufrido cambios y es importante que los conozcas. Así que, sin más, hablamos de Robots.txt y SEO.
Tabla de Contenidos
¿Qué es el archivo robots.txt?
El archivo robots.txt es un sencillo archivo de texto que sirve para indicar a las arañas de los distintos motores de búsqueda (no sólo a Google) a qué páginas o archivos de tu web pueden acceder y a cuáles no.

El archivo debe colocarse en el directorio base de la web:
https://www.miweb.com/robots.txt
En teoría, robots.txt no debería utilizarse para dejar páginas fuera de Google, sino que su uso debería limitarse a evitar la sobrecarga de solicitudes en la web.
Sin embargo, por la comodidad y efectividad que aporta, a menudo se utiliza para evitar que Google pueda ver qué hay en ciertas páginas y restringir su indexación.
¿Para qué sirve el robots.txt?
Como decíamos, robots.txt se utiliza para controlar el tráfico que las arañas de los motores de búsqueda generan a una web. Sin embargo, también se usa para mantener páginas fuera del alcance de dichos motores (especialmente de Google).
Así, en general, podemos asumir que el robots.txt puede usarse de los siguientes modos:
| Tipo de página | Gestión del tráfico | Ocultar de Google | Descripción |
| Página web (cualquier URL) | Sí | No | Para páginas web normales y ciertos tipos de archivos (HTML o PDF, por ejemplo) el uso de robots.txt se limita a evitar saturar el servidor o perder Crawl Budget. No es útil para no indexar páginas, porque, aunque estén bloqueadas por robots, se pueden indexar igualmente si hay otras páginas enlazando a la bloqueada. |
| Archivo multimedia (jpg, png, mp4, etc) | Sí | Sí | A diferencia del caso anterior, bloquear archivos multimedia por robots.txt sí evitará que se indexen. |
| Archivo de recurso (js, css, font, etc) | Sí | Sí | Sucede igual que en el caso anterior, pero tienes que tener en cuenta que, si el bloqueo de ciertos recursos dificulta a Google la renderización y comprensión de la página, es mejor no bloquearlos. |
Reglas del archivo Robots.txt en detalle
Vamos a explicar con un poco más de detalle cómo funciona el robots.txt y el sentido que tiene su sintaxis.
Tomemos como ejemplo el robots.txt más simple y que casi cualquier web montada en WordPress tiene cuando la creas por primera vez:
User-agent: *
Disallow: /wp-admin/
¿Qué significa lo que aparece en este robots.txt? Lo siguiente:
🔵 User-agent: con este término indicamos a qué arañas se aplica la directriz que especifiquemos más abajo.
🔵 *: el asterisco, como sucede en RegEx, sirve para indicar que nos estamos refiriendo a cualquier araña. Si en vez de un asterisco pusiese “Googlebot”, la directriz sólo aplicaría a Googlebot.
🔵 Disallow: esta es una directiva que dice a la araña dónde NO puede acceder.
🔵 /wp-admin/: esta es la ruta a la que le estamos especificando que NO puede acceder.
Además de lo anterior, conviene aclarar que la sintaxis de robots.txt funciona de forma secuencial. Es decir, lo que aparece debajo anula lo que aparece arriba (salvo algunas mínimas excepciones).
Así, si en una línea prohibimos a Googlebot acceder a /wp-admin/ y en la siguiente se lo permitimos, Google entenderá que le permites acceder.
Ahora que has entendido mínimamente cómo funciona la sintaxis de robots.txt, vamos a ver con un poco más de detalle los diferentes componentes de un robots.txt:
User-agent
Como dijimos, User-agent es la forma de identificar a la araña a la que queremos que se apliquen las directrices especificadas.
Cada araña tiene su propio nombre (por ejemplo, la araña de Google es Googlebot y la de Bing es BingBot). Por tanto, podemos bloquear específicamente los bots que consideremos oportuno.
Además, el User-agent es el elemento del robots.txt que comienza una serie de instrucciones.
Así, las instrucciones deben ir precedidas del User-agent al que se van a aplicar.
También hay que mencionar que las directrices especificadas entre dos User-agent se aplicarán únicamente al primer User-agent (porque, digamos, conforma un “bloque” de directrices).
Disallow
No hay mucho que explicar aquí. Como dijimos, es una directiva que nos permite evitar que el robot de turno acceda a una determinada ruta.
Allow
Allow es la directiva contraria a Disallow. Y podría parecer una tontería porque, por defecto, todas las páginas son accesibles a los robots, ¿no?
Pues no es una tontería, no.
Allow nos permitirá hacer excepciones a la norma Disallow.
Por ejemplo, imagina que tenemos una carpeta de contenidos en PDF a la que no queremos que los robots accedan. Sin embargo, hay un PDF concreto en esa carpeta al que sí queremos que sea accesible.
En ese caso, podemos usar esta sintaxis:
User-agent: *
Allow: /pdfs/pdf-que-queremos-indexar.pdf
Disallow: /pdfs/
De este modo, los robots ignorarán TODO lo que haya en la carpeta PDFs, con la excepción del PDF que le hemos indicado específicamente.
Es importante mencionar que, cuando se utilizan directivas conjuntas de este tipo, es mejor no utilizar el *, porque puede conducir a que haya conflictos entre las directivas.
Por cierto, este es uno de los pocos ejemplos en los que una directiva posterior no anula la anterior, y es así porque se interpretan en bloque.
Sitemap
Una práctica bastante habitual en los robots.txt es utilizarlo para indicar a los robots dónde está el sitemap de la web.
En origen, robots.txt no estaba pensado para esta labor, pero, actualmente la mayoría de los motores de búsqueda relevantes soportan esta función.
Es muy recomendable utilizar esta directriz, porque, aunque envíes tu sitemap a Google por tu cuenta, recuerda que hay muchos otros motores de búsqueda que pueden traernos tráfico. Así que es buena idea ponerles las cosas fáciles.
El uso es muy sencillo. Bastará con lo siguiente, por ejemplo:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://dominio.com/sitemap.xml
Sitemap: https://dominio.com/sitemap2.xml
Como ves, puedes indicar más de un sitemap y debes hacerlo con la ruta completa.
Crawl Delay
Crawl Delay es una directiva que, aunque no es oficial, se suele usar para limitar los accesos de los robots a tu web. No obstante, como no es oficial, no todos lo respetan (por ejemplo, Google no lo respeta).
Sea como sea, puedes utilizarlo del siguiente modo:
User-agent: BingBot
Disallow: /wp-admin/
Crawl-delay: 10
De esta forma, limitamos el crawleo de BingBot a nuestra web, evitando que la sobrecargue.
No obstante, ten en cuenta que si los robots de los buscadores están haciendo que tu web funcione mal, el problema no está en el robots.txt ni en las arañas, sino en una mala configuración de tu hosting.
Es eso lo que deberías arreglar en vez de hacer nada en robots.txt. Esto sólo será una (mala) solución temporal.
🥇 Alcanza los primeros puestos de Google optimizando tus contenidos con Kiwosan 🐴
Empezar prueba gratuita¿Qué limitaciones tiene el archivo robots.txt?
Robots.txt es un sistema bastante básico. Funciona, pero es bastante básico y, por tanto limitado. Cuando crees tus archivos robots.txt es importante que tengas esto en cuenta para que los crees de la forma adecuada.
Estas son las principales limitaciones que debes tener en cuenta en lo relativo a robots.txt:
No todos los motores de búsqueda hacen caso a robots.txt
Lo primero que debes tener en cuenta es que no todos los motores de búsqueda hacen caso al archivo robots.txt. Google sí, pero otros, no.
Digamos que robots.txt no permite “forzar” lo que hace la araña del motor de búsqueda, sino que le aconseja. Depende del diseño de la araña que ésta obedezca o no a la recomendación del robots.txt.
Por ejemplo, es célebre el caso de la araña de Screaming Frog, que puede hacerse pasar por la araña de Google o, directamente, ignorar las directivas que se le indiquen en robots.txt.
Lo cual, a nosotros, como SEOs, nos viene muy bien, dicho sea de paso.
Es por ello que, si quieres proteger alguna parte de tu web al 100%, no puedes limitarte a bloquearla por robots, sino que tienes que colocar una contraseña.
La sintaxis se interpreta de formas diversas
Otra limitación del archivo robots.txt es que no hay una única forma de interpretar la sintaxis que se utiliza en él.
Cada rastreador puede hacerlo de forma distinta y, como consecuencia, podría llegar a haber ciertas contradicciones. De modo que un rastreador actúe de una forma y otro rastreador actúe de la forma contraria ante la misma instrucción.
No obstante, hay que decir que, para las directrices básicas, todos entienden más o menos lo mismo.
Ante sintaxis más complejas sí puede haber algún problema adicional, como que alguna araña no comprenda lo que se le está indicando.
Una página bloqueada por robots.txt puede indexarse de todos modos
Esta última limitación es importante de cara al SEO, porque, en no pocas ocasiones, intentamos evitar la indexación de tal o cual página mediante robots.txt. Y robots.txt no está pensado para ello.
Esto implica que, por ejemplo, si el robot de Google rastrea tu web y encuentra una URL bloqueada por robots.txt, no la indexe.
Sin embargo, si rastrea otras webs y encuentra varios enlaces apuntando a dicha URL (que tú tenías bloqueada por robots), es posible que decida indexarla incluso sin haberla visitado.
Es por ello que, para evitar la indexación, es importante utilizar la metaetiqueta no-index, y no utilizar robots.txt para ello.
Buenas prácticas en robots.txt
Vamos a ver ahora algunas buenas prácticas con robots.txt, que te permitirán evitar problemas a la hora de diseñar las directrices para motores de búsqueda en tu web:
Cada directriz en una línea
Cuando crees tu robots.txt, no coloques todas las directrices en una única línea. Al contrario: cada directriz debería ir en una única línea.
De lo contrario, puedes confundir a los robots de los motores de búsqueda a la hora de parsear el contenido.
Así, por ejemplo, este robots.txt estaría MAL:
User-agent: * Disallow: /wp-admin/
Uso del *
El * se puede utilizar en múltiples ocasiones, como sucede en RegEx, no sólo para indicar cualquier User-agent.
Así, por ejemplo, podemos tener el siguiente robots.txt:
User-agent: *
Disallow: *?
En este robots.txt, indicamos a los robots que no accedan a ninguna URL que incluya un signo de interrogante (?). Esto puede ser útil para evitar que accedan a URLs con variables, evitando gastar en ellas Crawl Budget.
Uso del $
El signo $ también se utiliza en RegEx, como el signo *, y su uso en robots.txt, de nuevo, es similar.
En este caso, el signo $ nos permitirá indicar el final de una ruta. Por ejemplo:
User-agent: *
Disallow: *.php$
Con esta directriz, lo que estamos diciendo es que no pueden acceder a ninguna URL que termine en .php. Sin embargo, estamos permitiendo que accedan a URLs que NO terminan con .php.
Por ejemplo, una URL con parámetros, tal que “dominio.com/url.php?lang=es” sí sería accesible, porque no termina en .php.
Comentarios con #
En caso de que lo desees, puedes utilizar comentarios en el robots.txt. Para ello, lo único que debes hacer es utilizar el signo #.
Estos comentarios serán ignorados por los robots de búsqueda y sólo servirán para los humanos que lean el robots.txt.
Puedes utilizar el signo # tanto en líneas con directrices como en líneas sin directrices, tal que así:
# No permitimos el acceso a /wp-admin/
User-agent: *
Disallow: /wp-admin/
O
User-agent: *
Disallow: /wp-admin/ # No permitimos el acceso a /wp-admin/
Ambos casos son válidos y no generan conflictos.
Comprueba que tu archivo robots es correcto
Cuando hagas cambios, comprueba que todo está correcto con la herramienta oficial de Google:
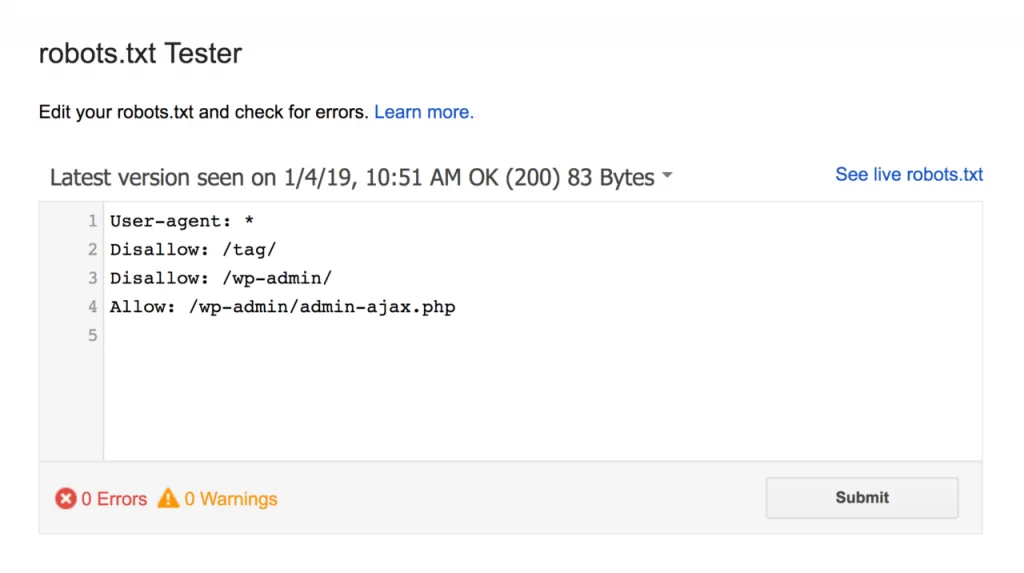
Otros consejos
Terminamos con algunas otras buenas prácticas que no requieren explicación:
🔵 Recuerda el orden de las directrices
🔵 Recuerda que sólo se usa un grupo de directivas por robot
🔵 Sé específico
🔵 Las directivas para todos los robots también aplican para robots específicos
🔵 Necesitarás un robots.txt para cada subdominio de tu web
Últimas novedades en robots.txt
Hace relativamente poco, Google actualizó su forma de relacionarse con robots.txt, y ahora, podemos indicarle más información.
Así, ahora podemos configurar directrices para ciertas IPs, IDNs, puertos y hostnames…
En fin, hay algunos aspectos adicionales que a la mayoría de la gente no le importan pero que si eres un SEO técnico sí te resultarán útiles.
🔗 Puedes echar un vistazo a las novedades aquí.
Como puedes ver, Robots.txt es importante en el SEO, porque es el archivo que nos permitirá indicar a Google cómo queremos que se comporte en nuestra web y decirle cómo queremos que se relacione con nosotros. ¡Por eso es fundamental que lo tengas bien optimizado!
Sigamos con la guía SEO definitiva. Ahora vamos a ver 👇🏻

Ángel Rodríguez es el CEO y fundador de Kiwosan.com
Ha trabajado más de 8 años como SEO, programador y redactor de contenidos.
Especializado en análisis de palabras clave, análisis de contenidos y de la competencia e Inteligencia Artificial.
Actualmente, también es redactor de los contenidos SEO del blog.

SEO para WordPress, la guía para mejorar el SEO de tu web

¿Qué son Topic Clusters y cómo usarlos en tu estrategia SEO?

Cómo hacer un análisis SEO de la competencia