
Seguimos con la serie de SEO Técnico: Crawl Budget. Hoy tocar ver otro concepto bastante técnico y que puede llegar a ser un dolor de cabeza para los SEOs. ¿Por qué? Sigue leyendo y lo descubrirás.
- Qué es el SEO Técnico
- Operadores y Footprints de Google
- Arquitectura web SEO
- Cómo indexar mi web en Google
- Qué es Robots.txt y para qué sirve
- Guía Crawl budget
- Que es un sitemap y como afecta al SEO
- Qué es Web Performance Optimization y Core Web Vitals
- Cómo solucionar el Contenido Duplicado y Thin Content
- Canibalización SEO
El bot de Google funciona recorriendo las distintas URLs de las distintas webs y descargando el contenido de dichas páginas.
Pero no puede dedicar un tiempo infinito a todas las webs. Por ello, asigna un tiempo de rastreo y descarga a cada web. Y eso es lo que conocemos como Crawl Budget. Hoy, hablamos de todo lo que debes saber sobre el Crawl Budget.
Tabla de Contenidos
¿Qué es el Crawl Budget?
El Crawl Budget, o presupuesto de rastreo, es un concepto asociado a los bots de los motores de búsqueda en relación a qué tiene que rastrear el bot, cuándo tiene que hacerlo y qué recursos tiene que dedicar para ese rastreo.
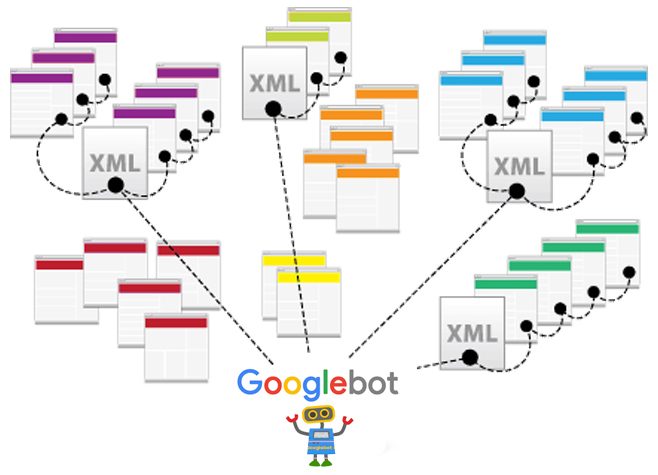
De forma resumida, podríamos decir que el Crawl Budget es un término para referirnos a cuánta atención prestan los motores de búsqueda a nuestro sitio web.
Para saber qué tiene que hacer el bot en nuestra web y cuanta atención nos tiene que prestar, intervienen unos cuantos factores que se pueden optimizar y veremos cómo hacerlo.
¿Por qué el Crawl Budget es importante para el SEO?
Como dueño de una web, te interesa tener cuantas más páginas rastreadas, mejor. Además, también te interesa que se rastreen tanto como sea posible.
¿Por qué?
Pues porque, de este modo, cada vez que añadas una nueva página, ésta será rastreada rápidamente y se añadirá al índice de los buscadores.
Lo mismo sucede con las actualizaciones de tus contenidos: cuanto antes se rastreen, antes se indexan los cambios.
Y, obviamente, cuanto antes se indexan las nuevas páginas o los cambios, antes puedes empezar a beneficiarte de dichas páginas o cambios.
En resumen
El Crawl Budget nos importa porque, cuanto más optimizado esté, más probabilidades tendremos de que tanto nuestras nuevas páginas como las actualizaciones de las páginas existentes se indexen en el menor tiempo posible.
Tengo una web pequeña… ¿Necesito atender al Crawl Budget?
Depende.
Si tienes una web pequeña porque es un micronicho de 20 páginas y no piensas hacer que crezca más, el Crawl Budget no debería quitarte el sueño.
Hasta que una página web no tiene unas 10.000 páginas o más, el Crawl Budget no es algo que merezca demasiada atención.
Sin embargo, si tienes una web pequeña porque acabas de empezar con ella, pero pretendes que crezca más adelante, sí deberías prestar atención al Crawl Budget.
¿Por qué?
Porque, aunque ahora no te haga falta, más adelante sí puede ser necesario optimizar el Crawl Budget. Y, si ya has hecho parte de las optimizaciones que mencionamos en el siguiente apartado desde el principio, tendrás trabajo adelantado.
¿Cómo se optimiza el Crawl Budget?
A la hora de optimizar el Crawl Budget, lo que tienes que hacer es, por un lado, aumentar tu Crawl Budget y, por otro, asegurarte de que no se pierde nada de ese Crawl Budget.
Veamos cómo hacerlo:
Hosting propio
De esto hablamos un poco más en un apartado más abajo, pero vamos a explicarlo rápidamente aquí: aunque cada web tiene su propio Crawl Budget, lo cierto es que los motores de búsqueda determinan el Crawl Budget en función del servidor.
Es decir, si estás en un hosting compartido, el Crawl Budget se dividirá entre las diferentes webs que hay en su interior, lo que significa que recibirás menos crawleo del que podrías recibir.
Para solucionarlo, contrata un plan de hosting para ti solo.
Actualiza y dota de popularidad a tu web
Otra forma de aumentar tu presupuesto de rastreo es haciendo tu web más popular y manteniéndola más actualizada (de esto también hablamos un poco más abajo).
Si mantienes la web actualizada y con popularidad, los motores de búsqueda entenderán que deben visitarla más a menudo para registrar en su índice los cambios que se vayan produciendo.
Para lograrlo, deberías actualizar más a menudo tu web y conseguir más backlinks, así como posicionar por una mayor cantidad de keywords.
🥇 Alcanza los primeros puestos de Google optimizando tus contenidos con Kiwosan 🐴
Empezar prueba gratuitaBloquea URLs con parámetros
Las URLs con parámetros no aportan información adicional ni nos interesan desde el punto de vista del SEO, porque son las mismas páginas que las básicas (sin parámetros).
Por ejemplo, piensa en una tienda online en la que los diferentes filtros de búsqueda conforman parámetros en la URL.
Si en una tienda buscamos zapatos de talla 34, azules y entre 30 y 60€, la URL puede ser algo así:
https://tiendaonline.com/zapatos/?talla=34&color=azul&precio=30-60Y si cambiamos la talla a 38 sería así:
https://tiendaonline.com/zapatos/?talla=38&color=azul&precio=30-60Pues bien, si todo eso es accesible por los robots de Google, estarás gastando tontamente presupuesto de rastreo, porque el robot estará pasando constantemente por páginas prácticamente iguales.
Para resolverlo, deberías bloquear por robots el acceso de las arañas a las URLs con parámetros según como sea la arquitectura web.
En el caso que hemos comentado sería algo así:
User-agent: *
Disallow: *talla=*
Disallow: *color=*
Disallow: *precio=*🔗 Te dejo por aquí una guía completa sobre el Robots.txt y cómo bloquear URLs.
Bloquea URLs duplicadas
Similar a lo anterior: si las arañas están accediendo a URLs duplicadas, estás perdiendo presupuesto de rastreo.
De hecho, podría suceder, incluso, que esas páginas las tengas con no-index (y con razón) y, aun así, el robot esté pasando por allí.
Obviamente, esto consume presupuesto de rastreo sin aportarnos ningún valor.
Para solucionarlo, bloquea desde robots.txt el acceso a contenidos duplicados.
Bloquea contenidos de baja calidad
En el caso de que tengamos páginas con contenidos de poca calidad que no estemos indexando (por ejemplo, ciertas etiquetas o patrones de URL que son útiles para el usuario, pero no para el SEO), también deberíamos bloquearlos.
Si no lo hacemos, ocurrirá como en los casos anteriores: estaremos gastando presupuesto de rastreo en URLs inútiles.
Para resolverlo, de nuevo, bloquea dichos contenidos desde robots.txt.
Arregla enlaces rotos y redirecciones
Los enlaces rotos son enlaces que se siguen y conducen a URLs donde no hay nada. Por su parte, las redirecciones son URLs que conducen a una tercera URL.
En ambos casos, consumen presupuesto de rastreo tontamente.
Por ello, si queremos optimizar nuestro Crawl Budget, deberíamos arreglar dichos enlaces y bloquear las URLs con redirecciones (para que las arañas accedan directamente a la URL buena, la final tras la redirección).
Arregla tus sitemaps
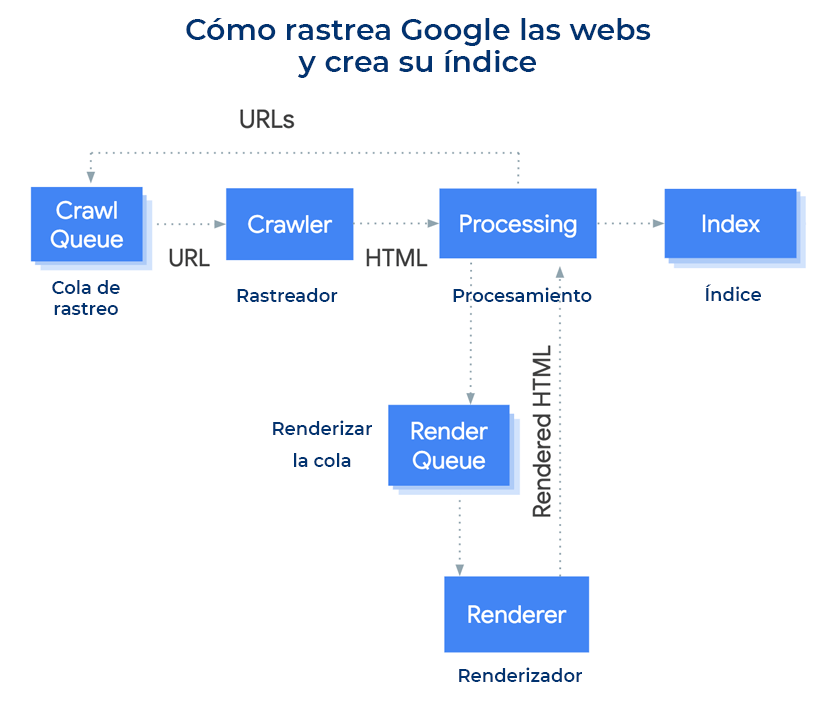
Los sitemaps son el índice de URLs al que acceden los robots de los motores de búsqueda para saber qué URLs rastrear (no es la única forma en que rastrean tus URLs, pero es una de ellas), por lo tanto, si hay errores, tendrás problemas en cuanto a presupuesto de rastreo.
Por ejemplo, si tienes muchas URLs con errores o con redirecciones, los robots accederán a ellas.
Por ello, corrige y arregla tus sitemaps.
Reduce el tiempo de carga
El presupuesto de rastreo no tiene un límite de páginas que rastrear, sino un límite de tiempo y de descarga.
Esto significa que dos webs con el mismo presupuesto de rastreo pueden tener diferente cantidad de URLs rastreadas si tienen diferentes velocidades de carga y peso de las páginas.
La web más ligera tendrá más URLs rastreadas que la más pesada.
Por tanto, mejorar la velocidad de carga es clave para optimizar el Crawl Budget.
Optimiza la estructura de enlaces de tu web
Por último, deberías optimizar la estructura de enlaces de tu web, para que los robots de los motores de búsqueda puedan navegar por las diferentes URLs sin problemas.
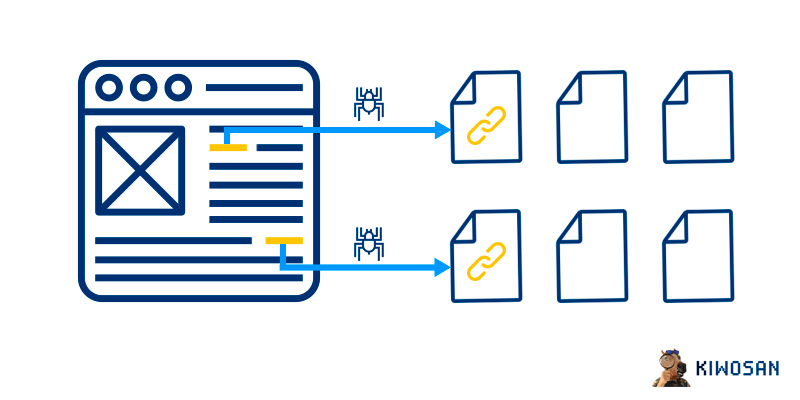
Para ello, evita, por ejemplo, bucles de enlaces o estructuras excesivamente complejas. Pónselo fácil y sencillo al usuario y a los robots de los buscadores.
Preguntas frecuentes sobre el Crawl Budget
Para terminar, vamos a resolver algunas dudas habituales en lo que a Crawl Budget se refiere:
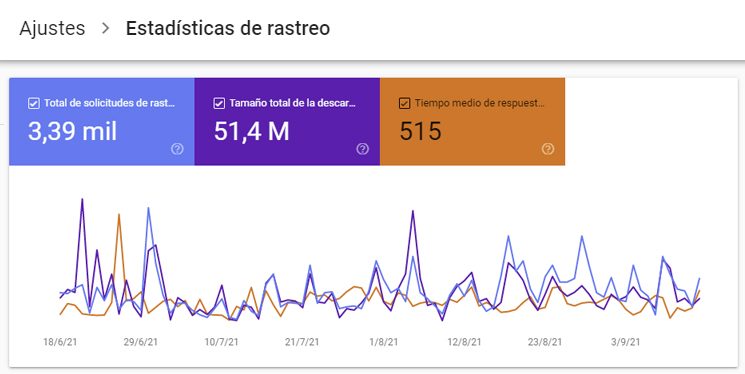
¿Dónde puedo ver el Crawl Budget de mi web?
Desde Search Console (Ajustes => Estadísticas de Rastreo) puedes ver un reporte de rastreo muy completo de tus webs donde te dice todas las páginas vistas, los recursos dedicas y el tiempo medio que ha tardado.
🔗 Ver reporte de rastreo de Search Console
¿Por qué los motores de búsqueda asignan Crawl Budget a los sitios web?
Los motores de búsqueda no tienen recursos ilimitados, y cada visita a tal o cual URL de una web les supone un coste en tiempo y dinero.
Puesto que su objetivo es visitar e indexar todas las webs que hay en la red (teórica e idealmente), lo que hacen es asignar un presupuesto de rastreo a cada web.
Con ello, lo que consiguen es tener un muestreo más amplio de todas las webs que hay en la red, aunque algunas de ellas no estén 100% rastreadas el 100% del tiempo.
En resumen, el Crawl Budget es una forma que tienen los motores de búsqueda de optimizar el rastreo de la red, priorizando unas webs sobre otras.
¿El Crawl Budget aplica únicamente a las páginas?
En este tipo de guías nos referimos a páginas para facilitar las explicaciones, pero lo cierto es que el Crawl Budget no se limita a las URLs, sino que también se gasta presupuesto de rastreo en el crawleo de cualquier otro tipo de archivo o documento.
Algunos ejemplos de elementos que consumen presupuesto de rastreo y no son URLs son:
- JavaScript
- CSS
- Variantes para móvil
- Variantes por idioma
- Archivos multimedia
- Archivos PDF
¿Qué determina el Crawl Budget?
El Crawl Budget que los motores de búsqueda asignan a las webs se basa en los siguientes dos factores:
1. Límite de crawleo o host load: esto hace referencia a la cantidad de crawleo que una web pude asumir y qué desea el dueño de la web en términos de crawleo.
2. Demanda de crawleo o crawl scheduling: qué URLs merecen más re-crawleo en función de su popularidad y cada cuánto se actualizan.
Puesto que, en general, los webmasters queremos tener la mayor cantidad de crawleo posible, lo normal es que el Crawl Budget se determine, sobre todo, en función del segundo punto.
¿Cómo funciona el límite de crawleo o host load en la práctica?
El límite de crawleo es estipulado por los motores de búsqueda con el objetivo de no sobrecargar el servidor de la web que están visitando.
Para ello, se basan en diferentes factores, siendo los dos más destacados los siguientes:
1. Cuán a menudo las peticiones a URLs devuelven errores de servidor o de timeout.
2. La cantidad de webs que están funcionando sobre un mismo servidor.
Respecto a este último punto, piensa que el límite de crawleo no se determina a nivel de web, sino a nivel de servidor. Esto significa que, si utilizas un servidor compartido, compartirás el presupuesto de rastreo con otras webs.
¿Cómo funciona la demanda de crawleo o crawl scheduling en la práctica?
Como explicamos un poco más arriba, la demanda de crawleo hace referencia a cuán a menudo una página debe ser re-crawleada.
Los motores de búsqueda determinan esto en función de varios factores, siendo los más destacables los siguientes:
1. Popularidad. Tanto la cantidad de keywords por las que está posicionando la página como la cantidad de backlinks que recibe entran en el cómputo de cuánto crawleo merece la página. Una página popular merece más crawleo que una poco popular.
2. Actualización. Si la página de actualiza a menudo, recibirá más crawleo que si no se actualiza.
3. Tipo de página. El tipo de página también afecta al presupuesto de crawleo, puesto que la página de política de privacidad y la página de “últimas entradas” no se espera que se actualicen con la misma asiduidad.
Sobre canonicals y meta-robots
Para terminar, un pequeño comentario sobre los canonicals y los meta-robots, como la meta-etiqueta no-index.
Debes entender que esas etiquetas se utilizan para informar a Google de qué debería indexar y qué páginas debería considerar importantes y principales, pero no le informa de si debe rastrear o no dichas páginas.
Es decir, una página con no-index y un canonical apuntando a otra página seguirá siendo rastreada y, por tanto, seguirá consumiendo Crawl Budget.
Si quieres evitar el rastreo de dichas páginas, debes bloquearlas por robots.txt.
Como puedes ver, el Crawl Budget es fundamental en SEO, porque, si no lo optimizamos, perderemos rastreo por parte de Google, y eso conducirá a que estemos menos actualizados en su índice y que tarde más en indexar nuestros nuevos contenidos.
Sigamos con la guía SEO definitiva. Ahora vamos a ver 👇🏻

Ángel Rodríguez es el CEO y fundador de Kiwosan.com
Ha trabajado más de 7 años como SEO, programador y redactor de contenidos.
Especializado en análisis de palabras clave, análisis de contenidos y de la competencia.
Actualmente también es redactor de los contenidos SEO del blog.

Cómo hacer una auditoría de contenidos SEO Profesional

Qué es una Auditoría de SEO técnico y cómo hacerla paso a paso

¿Qué es E-A-T? Por qué es importante en tu ESTRATEGIA SEO